



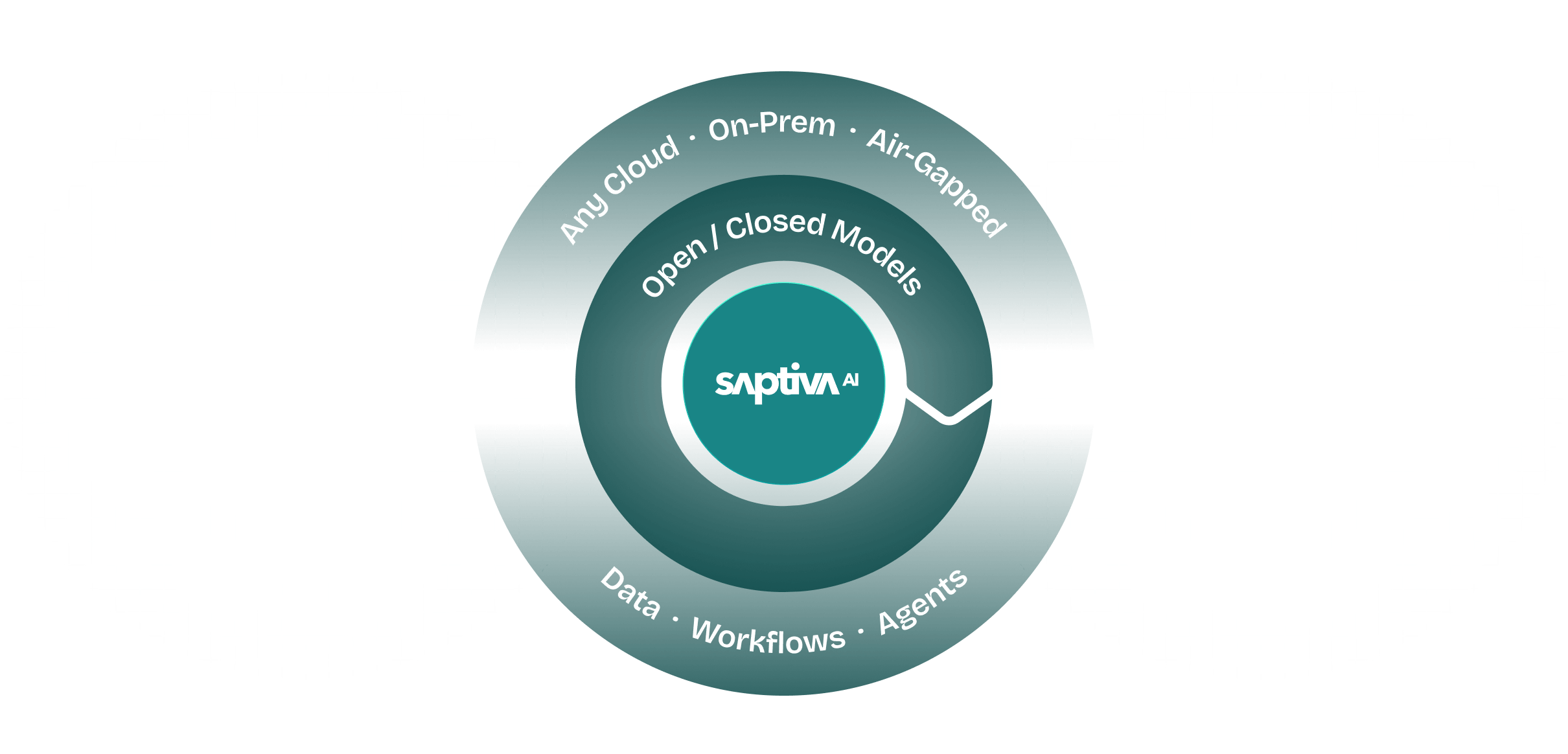
Saptiva gives you full control over AI, from model orchestration to deployment in cloud, hybrid, on-prem, or air-gapped environments. Built in LatAm for regulated industries and high-security workloads. No data exit. No lock-in. Complete control.
Built for independence, with seamless hyperscaler integration when required.








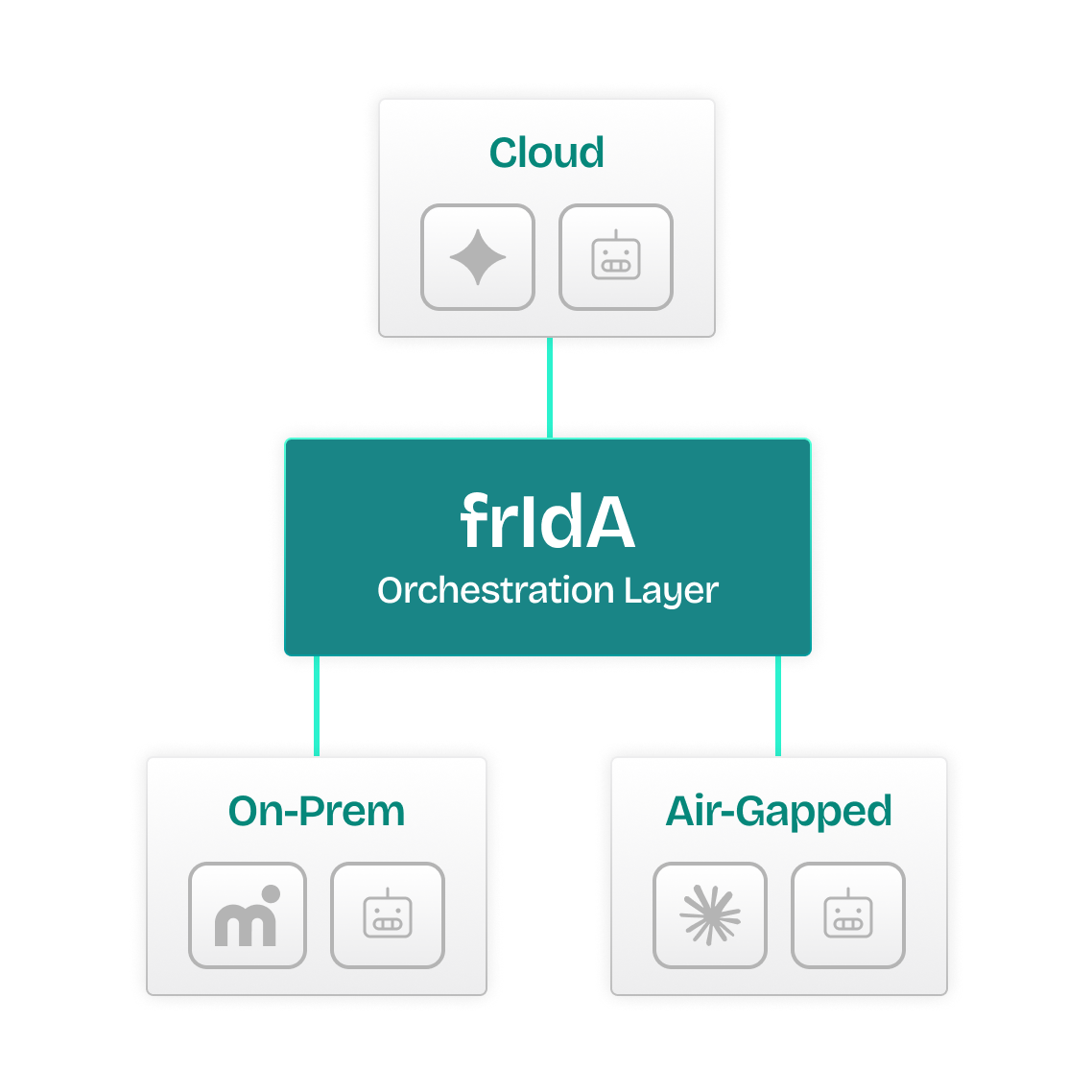
Saptiva Cloud delivers a full-stack AI environment built to support the needs of developers, enterprises, and public institutions in Latin America. Whether deployed in public cloud zones, on-prem infrastructure, hybrid environments, or fully air-gapped systems, your data, models, and pipelines remain fully under your control.
Built from the ground up to meet regional regulations, privacy requirements, and enterprise performance standards.
Full control over your AI, from compute to deployment. Saptiva runs in the cloud, on-prem, hybrid, or in air-gapped environments, with zero lock-in and complete data governance.
Run open or closed models, including LLaMA, Qwen, Grok, and more. Secure execution without vendor lock-in.
Route inference workloads across clusters, edge nodes, or air-gapped zones for optimal performance, latency, and compliance.
A unified orchestration layer that manages environments, workloads, agents, and observability with full API and CLI access.
Scale from a single GPU to distributed clusters. Growth is driven by workload demand, not provisioning limits.
Cloud, on-prem, hybrid, or air-gapped. Saptiva adapts to your infrastructure and compliance needs, with unified orchestration through frIdA.
Your AI. Your Stack.
Unified, Secure, and Fully Under Your Control.
From banking to government, Saptiva meets the highest standards of data protection and compliance with zero exposure and zero compromise.
Join the Grid
All workloads run inside your infrastructure with no shadow compute, no external transfer, and no exposure.

Designed to meet the needs of banks, public institutions, and critical sectors across Latin America.

Encryption in transit and at rest, isolated compute, role-based access control, and full observability built in.
Saptiva gives teams the tools to move fast with CLIs, SDKs, APIs, and native agent support. Everything is designed for real-world deployment and production operations, not demos.

CLIs, SDKs, and APIs that give developers fast, programmatic control of agents, models, and pipelines.

Trace every step, monitor latency, and audit workloads in real time, with full visibility and no black boxes.

Deploy intelligent agents inside your stack using your models, your data, and your logic.



© 2025 Saptiva, INC. All rights reserved.



